When Requirements Hide in Plain Sight: Lessons from a Cloud Migration Conversation
There’s a particular kind of joy in collaborating with customers who are at the beginning of their cloud journey. It reminds me of my own early days—full of questions, brimming with possibilities, and, sometimes, stumbling over nuances that only experience can reveal.
Recently, I had the opportunity to work with a small Swiss company looking to move one application to the cloud. Their destination was still open, would it be db@azure, db@gcp, or Oracle’s own OCI? What was clear, however, was their desire for Autonomous Shared and a non-negotiable requirement: the data had to reside within Switzerland.
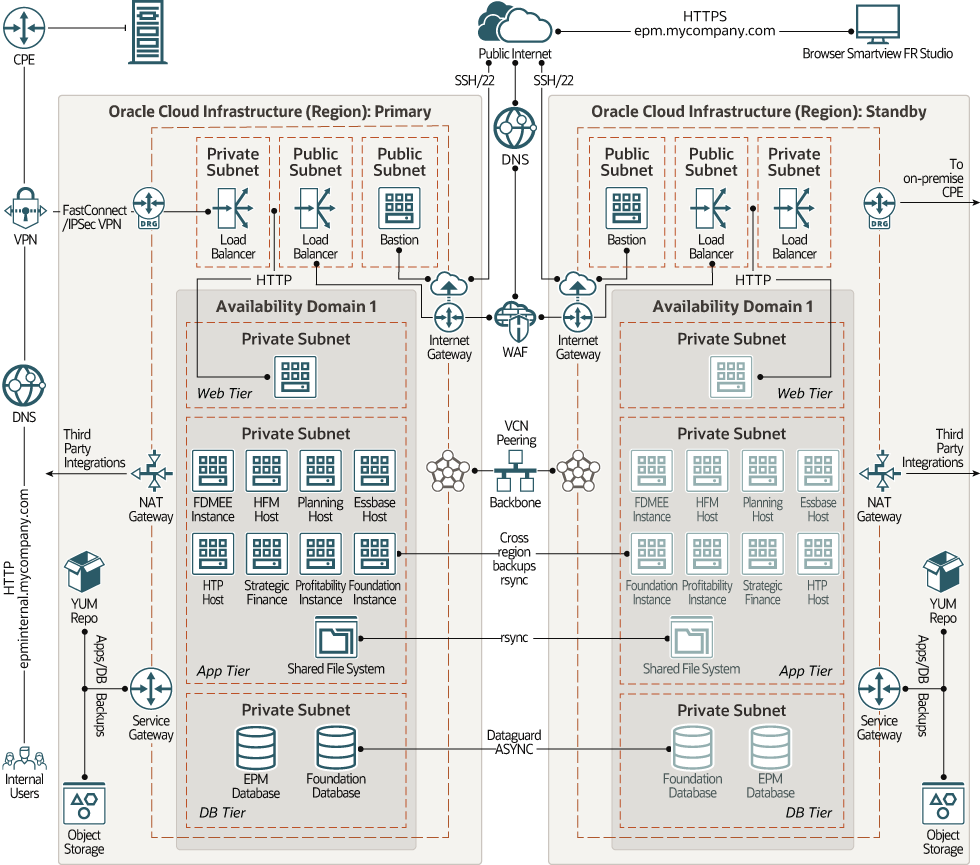
During our discovery call, the customer mentioned their production database was set up with Data Guard. That phrase sent our internal gears spinning. Immediately, we zoomed in on Disaster Recovery: Could we achieve cross-region DR within Switzerland? OCI, after all, only offers a single data center here, so fulfilling this with cross-region DR – and adhering to data residency laws – seemed almost impossible. Our team debated back and forth, searching for possibilities, feeling that familiar tug-of-war between technical constraints and customer expectations.
But something wasn’t adding up. Our customer was a small company, and cross-region DR seemed… ambitious. I couldn’t shake the feeling that we might be fighting the wrong battle. Instead of pushing forward, I suggested a simple detour: “Let’s do a follow-up call. Let’s ask how they have things set up today.”
On that next call, we asked. The answer was refreshingly straightforward: their current production system ran on two physical servers, sharing the same data center. There was no second location, no elaborate DR strategy—just local High Availability. The reference to Data Guard? Not about disaster recovery, but about making the application resilient within their one Swiss facility.
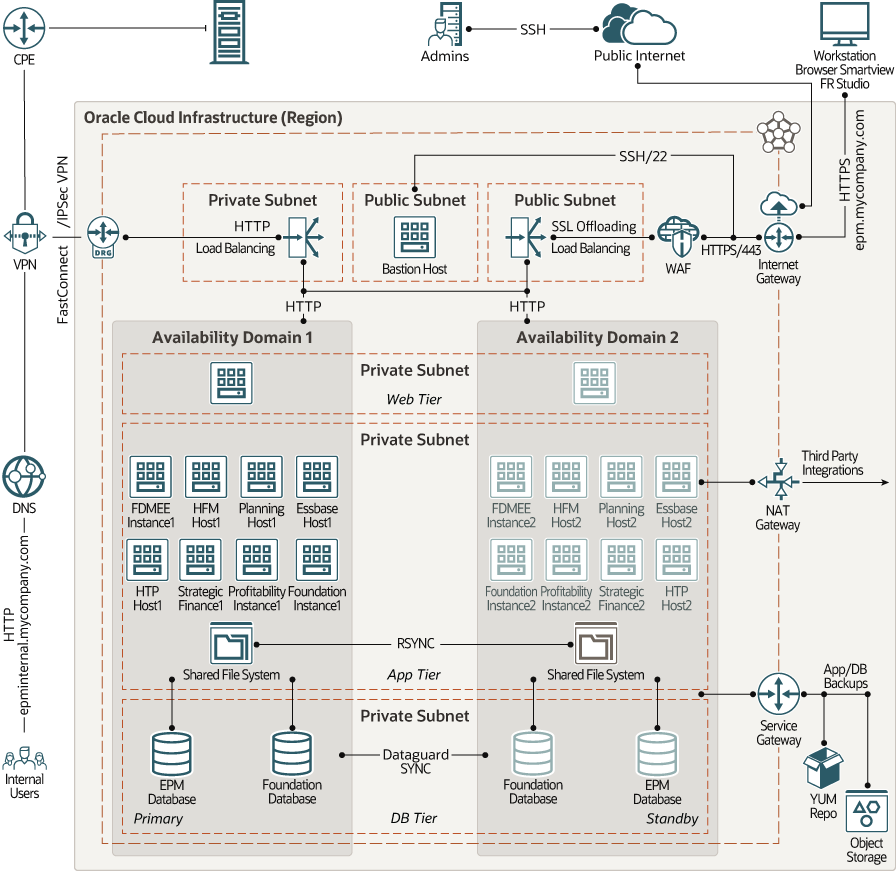
Suddenly, everything made sense. What we interpreted as a DR requirement was, in reality, a need for High Availability. OCI’s Swiss region, with its multiple fault domains, could easily support this – no cross-region headaches, no impossible trade-offs.
The Lessons I Carried Forward
You’d think, after years in technology, that reading requirements would become second nature. But cloud brings a new lens—and some familiar assumptions don’t always translate.
Lesson 1: On-Prem Is Not Cloud.
Many customers run Data Guard between two on-prem data centers simply because the infrastructure already exists. In the cloud, approaches—and terminology—can shift. Our job isn’t just to map tech to tech, but to truly understand the business need behind each architectural choice.
Lesson 2: Ask Better Questions.
Not all customers need Maximum Availability Architecture (MAA). The “right” level of redundancy depends on service level agreements, acceptable recovery times (MTTR), and, sometimes, simple practicality. Before designing a solution, step back and listen. A question as basic as “How are you doing this today?” can reveal the heart of the matter.
In the end, finding clarity isn’t about having all the answers—it’s about asking the questions that matter. Here’s to more follow-up calls, fewer assumptions, and, hopefully, some lessons you can carry into your own customer journeys
Further Reading
If you’re interested in the technical details behind High Availability on Oracle Cloud Infrastructure, here are some resources to explore:
Fault Domains and Availability Domains
Fault domains are logical groupings of hardware within an availability domain, designed to protect against unexpected hardware failures or planned outages. By distributing resources across different fault domains and availability domains, you can improve the resilience and uptime of your applications. Learn more in the official Oracle Documentation.
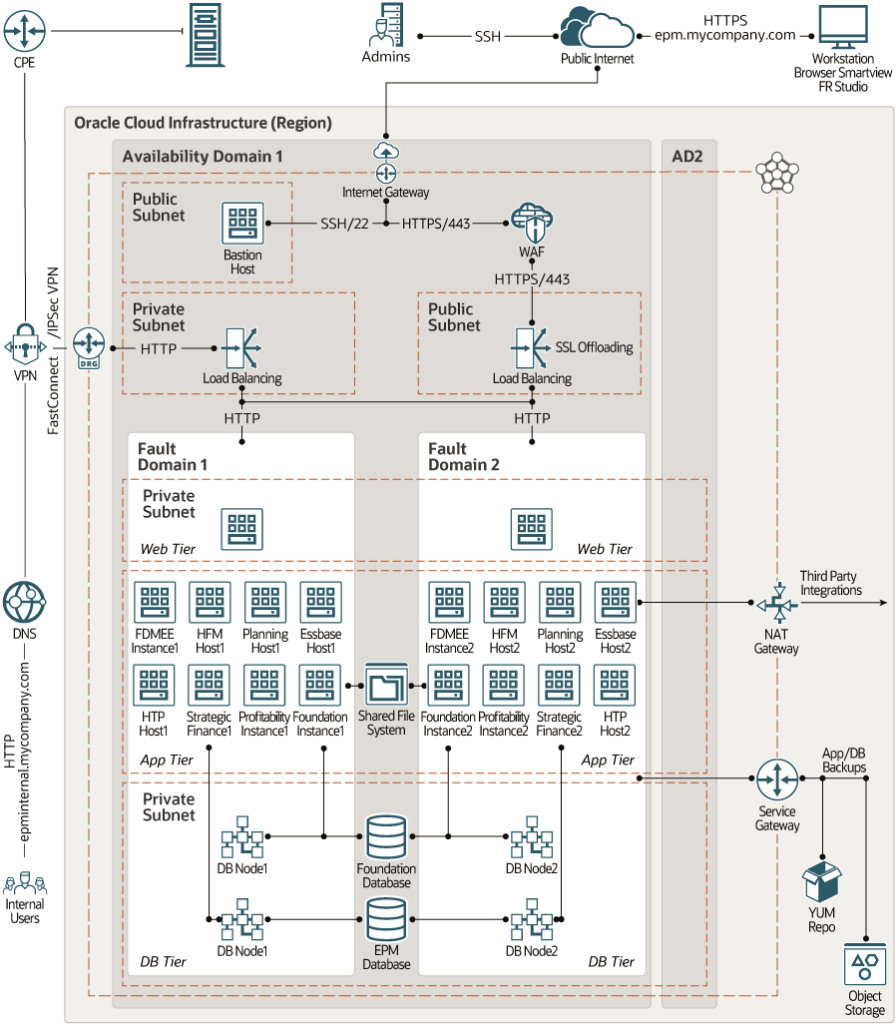
Sample HA Architecture: Single Availability Domain (for Hyperion)
This diagram outlines a highly available architecture within a single availability domain, showing how services and databases can be distributed for better fault tolerance—even without multiple regions or data centers.
Single Availability Architecture Diagram